機械学習によるマルウェア検出に入門してみた
この記事はIPFactory Advent Calendar 2022の21日目の記事です。
はじめに
今回は、遅ればせながら先日購入した『セキュリティエンジニアのための機械学習』を参考に機械学習によるマルウェア検出に入門してみました。
環境の準備
書籍で推奨されていたGoogle Colaboratoryを使用しました。
Google Colaboratoryは、ブラウザ上でPythonを記述・実行できるサービスです。 機械学習で利用する数多くの外部ライブラリがインストールされており、基本無料でGPUやTPUといったハードウェア機能を利用することができます。
機械学習アルゴリズム
今回はロジスティック回帰を利用してマルウェアの検出器を作成してみます。
探索的データ解析
早速マルウェア検出器の作成に移るのですが、まずは探索的データ解析を行います。 探索的データ解析とは、データの集計や可視化を行うことでデータの異常や特徴を調べることです。
データセット
データセットは研究等での使用を目的として、Webサイトからマルウェアの検体を入手することができますが、
今回は書籍のサンプルデータとしてGitHubに置かれているPrateek Lalwaniさんによって提供されているマルウェアのデータセットを利用しました。
pandasライブラリと探索的データ解析が素早くできるオープンソースのpandas_profilingパッケージを利用してデータの読み込みとデータセットの分析を行います。
# 必要なパッケージのロード import pandas as pd import pandas_profiling # csvファイルから"|"区切りでデータを読み込み MalwareDataset = pe.read_csv('MalwareDataset.csv', sep = '|') # 最小限の情報のみを出力 pandas_profiling.ProfileReport(MalwareDataset, minmal=True)
実行すると以下のように項目ごとに集計され出力され、
Variable typesから2項目がカテゴリ変数、55項目が数値型の項目であることが分かります。

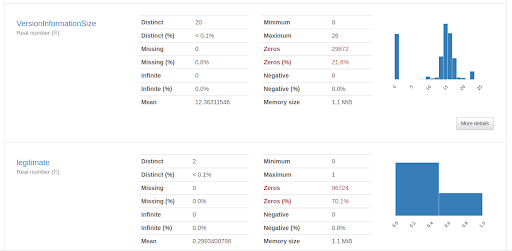
まずは、ロジスティック回帰を利用した検出器を作成してみます。
# 必要なパッケージをロード from sklearn.linear_model import LogisticRegression # ロジスティック回帰 from sklearn.metrics import accuracy_score # 検出器の正解率を出力 from sklearn.model_selection import train_test_split # データセットの分割 # カテゴリ変数の「Name」「md5」とラベルとなる「legitimate」を除いた列(axis=1) X = MalwareDataset.drop(['Name','md5','legitimate'], axis=1) # ラベル「legitimate」 y = MalwareDataset['legitimate'] # ソルバーにL-BFGS法を指定したロディスティック回帰を使った検出器を作成 detector= LogisticRegression() # 訓練用データで検出器を訓練 predictions = detector.predict(X_test) # 検出器の正解率を出力 accuracy = 100.0 * accuracy_score(y_test, predictions) print(accuracy)
# 出力結果 70.50344078232524
調べてみるとどうやらLogisticRegression()ではL-BFGS法以外のソルバーを選択することができるようだったので、色々と試してみました。
| solver | 詳細 | 正解率 |
|---|---|---|
| lbfgs | L-BFGS法 | 70.50344078232524 |
| newton-cg | ニュートン共役勾配法 | 95.63201738500543 |
| liblinear | liblinearライブラリ 小さなデータセットだと早い |
30.028975009054694 |
| sag(Stochastic Average Grandient) | 確率的勾配降下法(SAG)の進化したもの 大きなデータセットだと早い | 29.496559217674758 |
続いてL-BFGS法で交差検証を行ってみます。
交差検証は、まずデータを任意の数K個に分割して一つをテストデータとします。その他すべてを訓練データとし評価を行うことをテストデータが毎度異なるようにK回繰り返します。 これらの結果の平均を取ることでデータの方よりがあった場合の性能の低下を防ぎます。
# 必要なパッケージのロード from sklearn.model_selection import cross_validate # 交差検証 from sklearn.model_selection import cross_val_score # 交差検証(K=8) scores = cross_val_score(detector, X_train, y_train, cv=8) # 結果の出力 print(100*scores.mean())
# 出力結果 69.95662689197374
今回は8分割交差検証の結果を出してみましたが、こちらも約70%という結果になりました。
終わりに
今回はロジスティック回帰を利用した検出器の作成のみでしたが、近いうちにハイパーパラメータの最適化やその他のアルゴリズムを用いた検出器の構築もしてみたいと思います。 T-potで収集したマルウェアで実際に検出できるのか試してみるのも面白そうです。
参考記事・サイト
この記事はIPFactory Advent Calendar 2022の21日目の記事です。 昨日はn01e0先輩によるchromolyでした。明日はriiriiriiさんの記事です。